RAG Explained in 12 Minutes
Aishwarya Srinivasan
Overview
This video explains Retrieval Augmented Generation (RAG), a crucial architecture for enterprise AI applications. It clarifies what RAG is, debunks common misconceptions like RAG being dead or obsolete due to larger context windows, and details its core components and various advanced patterns. RAG combines a retrieval system to find relevant information with a large language model (LLM) to generate answers, grounding them in factual data rather than relying solely on the LLM's training. The video emphasizes RAG's importance for building reliable AI systems in production, covering ingestion, embedding, vector databases, and retrieval strategies, before diving into ten distinct RAG patterns designed to address specific challenges and enhance performance.
Save this permanently with flashcards, quizzes, and AI chat
Chapters
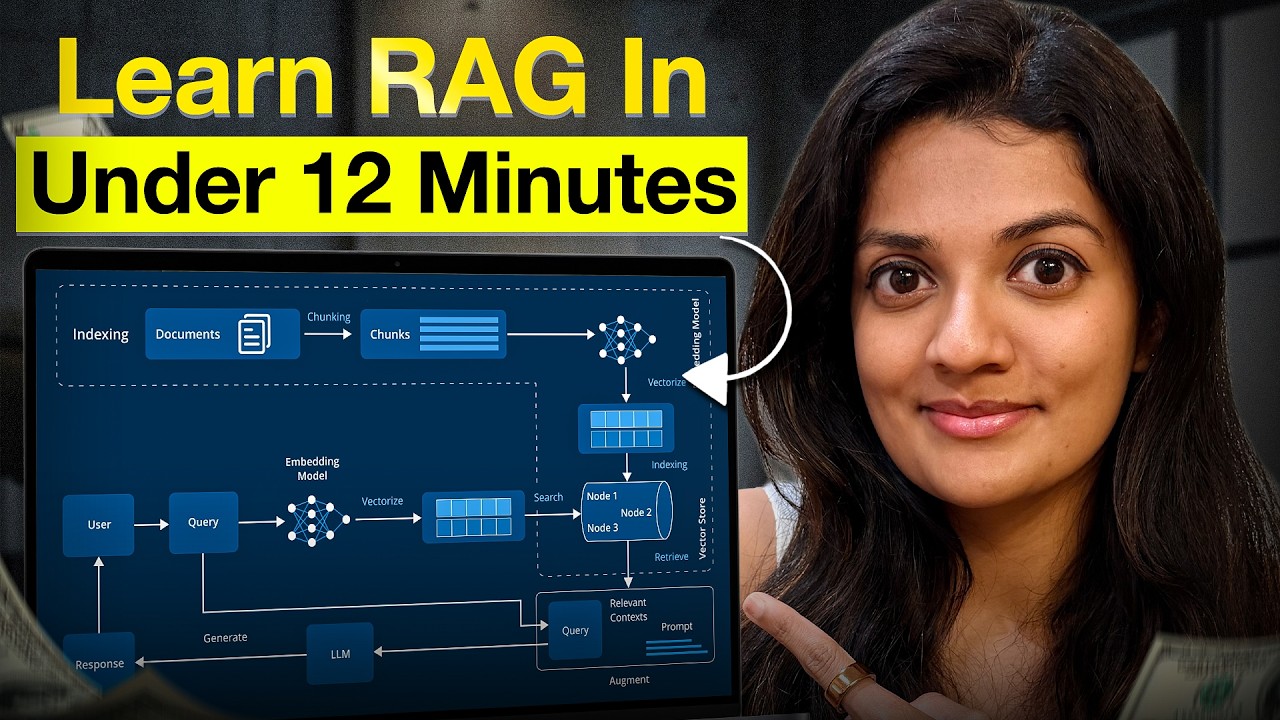
- RAG, or Retrieval Augmented Generation, allows Large Language Models (LLMs) to access and use external, up-to-date information beyond their training data.
- It functions like an open-book exam for an LLM, where it retrieves relevant information before generating an answer, ensuring the answer is grounded in facts.
- RAG is a foundational pattern for almost all serious enterprise AI applications, including customer support, internal knowledge assistance, and legal document analysis.
- Standard LLMs have knowledge cutoffs and lack access to private or real-time data, which RAG overcomes.
- The idea that RAG is 'dead' is false; RAG is an evolving architectural pattern, not a single static technology, with new patterns emerging to address limitations.
- Larger context windows in LLMs do not eliminate the need for RAG because stuffing excessive, irrelevant data increases costs, latency, and degrades model performance.
- RAG's purpose is to precisely surface the most relevant information, which brute-force context stuffing cannot achieve efficiently or accurately.
- Well-implemented RAG systems outperform simple context stuffing in accuracy, cost, and speed.
- Ingestion involves breaking down documents into manageable pieces (chunks) and storing them for retrieval.
- Chunking strategies range from fixed-size to semantic (topic-based) and document-aware (structure-based), with hierarchical (small-to-big) chunking being a production-ready technique.
- Embedding models convert text chunks and user queries into numerical vectors that capture semantic meaning, enabling similarity searches.
- Vector databases store these embeddings and facilitate fast, efficient similarity searches.
- Retrieval strategies focus on finding the most relevant chunks based on query embeddings, often enhanced by metadata filtering and hybrid search.
- Simple RAG is basic retrieval and generation, suitable for prototyping but insufficient for production.
- Patterns like 'branched RAG' decompose complex questions into sub-questions, while 'adaptive RAG' intelligently decides if retrieval is needed at all.
- 'Hypothetical Document Encoding (HyDE)' improves retrieval by embedding a generated hypothetical answer to the query.
- Advanced patterns like 'corrective RAG' add evaluation steps to ensure retrieved documents are high-quality, and 'self-RAG' uses the LLM to critique its own reasoning.
- 'Agentic RAG' uses LLMs as orchestrators to perform multi-step actions, including retrieval, API calls, and code execution, representing the future direction of RAG.
- Multimodal RAG handles various data types (images, charts) by describing them textually or embedding them, while 'Graph RAG' leverages knowledge graphs to understand relationships between data points.
Key takeaways
- RAG is an essential architectural pattern for making LLMs useful and reliable in real-world applications by grounding their responses in external data.
- Misconceptions about RAG's obsolescence are incorrect; RAG is a maturing field with innovative patterns addressing its limitations.
- Effective RAG implementation relies on careful choices in data ingestion (chunking), embedding models, and vector database selection.
- Different RAG patterns exist to solve specific problems, ranging from simple retrieval to complex agentic workflows and multimodal data handling.
- The goal of RAG is to improve LLM accuracy, reduce hallucinations, and provide contextually relevant answers cost-effectively.
- Advanced RAG patterns like Agentic RAG and Graph RAG represent the cutting edge, enabling more sophisticated and interconnected AI reasoning.
- Understanding the trade-offs between different RAG approaches is key to building production-ready AI systems.
Key terms
Test your understanding
- What is the fundamental problem that RAG solves for Large Language Models?
- Why is the claim that RAG is 'dead' incorrect, and how is the technology evolving?
- How does semantic chunking differ from fixed-size chunking, and why is it often preferred?
- What is the role of embedding models and vector databases in the RAG architecture?
- How does a pattern like Agentic RAG differ from Simple RAG in its approach to problem-solving?
- What are the practical limitations of simply increasing an LLM's context window instead of using RAG?