Vendor Performance Data Analytics End-To-End Project | SQL + Python + Power BI + Reporting (ENG-SUB)
Tech Classes
Overview
यह वीडियो एक एंड-टू-एंड डेटा एनालिटिक्स प्रोजेक्ट का विस्तृत विवरण प्रदान करता है, जिसमें SQL, Python और Power BI का उपयोग करके वेंडर के प्रदर्शन का विश्लेषण किया जाता है। यह प्रोजेक्ट वास्तविक दुनिया की कंपनियों के मानकों को ध्यान में रखकर बनाया गया है, जो सामान्य शुरुआती स्तर के प्रोजेक्ट्स से अलग है। इसका उद्देश्य रिक्रूटर्स को प्रभावित करने के लिए एक मजबूत पोर्टफोलियो बनाना है। वीडियो में डेटाबेस में डेटा को इंजेस्ट करने, SQL का उपयोग करके डेटा को एक्सप्लोर करने, Python में डेटा को क्लीन करने और विश्लेषण करने, और अंत में Power BI में एक इंटरैक्टिव डैशबोर्ड बनाने की प्रक्रिया को समझाया गया है। यह प्रोजेक्ट सिखाता है कि कैसे विभिन्न डेटा स्रोतों को एकीकृत किया जाए और व्यावसायिक समस्याओं को हल करने के लिए उपयोगी इनसाइट्स निकाले जाएं।
Save this permanently with flashcards, quizzes, and AI chat
Chapters
- यह प्रोजेक्ट वास्तविक दुनिया की कंपनियों के मानकों पर आधारित है, न कि शुरुआती स्तर के प्रोजेक्ट्स पर।
- इसका लक्ष्य एक मजबूत पोर्टफोलियो बनाना है जो रिक्रूटर्स को प्रभावित करे।
- यह सिखाता है कि SQL, Python और Power BI जैसे विभिन्न टूल्स को एक ही प्रोजेक्ट में कैसे एकीकृत करें।
- यह उन सामान्य समस्याओं को हल करता है जिनका सामना डेटा एनालिस्ट करते हैं, जैसे कि बेसिक प्रोजेक्ट्स से जॉब मिलना, मल्टीपल स्किल्स को इंटीग्रेट करना, और सही इनसाइट्स निकालना।
- प्रोजेक्ट की मुख्य व्यावसायिक समस्या रिटेल और होलसेल इंडस्ट्री में प्रभावी इन्वेंटरी और सेल्स मैनेजमेंट के माध्यम से लाभप्रदता को अनुकूलित करना है।
- मुख्य लक्ष्य अंडर-परफॉर्मिंग ब्रांड्स की पहचान करना, टॉप वेंडर्स का पता लगाना, बल्क परचेजिंग के प्रभाव का विश्लेषण करना, इन्वेंटरी टर्नओवर का आकलन करना और वेंडर्स के बीच लाभप्रदता के अंतर की जांच करना है।
- प्रोजेक्ट का फ्लो: व्यावसायिक समस्या को परिभाषित करना, डेटा को SQL का उपयोग करके एक्सप्लोर करना, Python में EDA और डेटा क्लीनिंग करना, रिसर्च प्रश्न हल करना, और Power BI में डैशबोर्ड बनाना और रिपोर्ट तैयार करना।
- प्रोजेक्ट में उपयोग किए जाने वाले विभिन्न CSV फ़ाइलों को SQLite डेटाबेस में इंजेस्ट किया जाता है।
- डेटा इंजेक्शन के लिए Python (Pandas, SQLAlchemy) का उपयोग करके एक स्क्रिप्ट बनाई जाती है, जिसमें लॉगिंग और एरर हैंडलिंग शामिल है।
- बड़े डेटासेट को संभालने के लिए डेटा को सीधे डेटाबेस में स्टोर करना महत्वपूर्ण है, न कि केवल CSV फ़ाइलों से विश्लेषण करना।
- स्क्रिप्टिंग का उपयोग डेटा को स्वचालित रूप से डेटाबेस में लोड करने के लिए किया जाता है, जो वास्तविक कंपनी परिदृश्यों में एक सामान्य अभ्यास है।
- डेटाबेस में मौजूद विभिन्न टेबलों (जैसे 'purchases', 'sales', 'vendor_invoice') को SQL का उपयोग करके एक्सप्लोर किया जाता है।
- प्रत्येक टेबल में डेटा के प्रकार, रिकॉर्ड की संख्या और कॉलम की जानकारी को समझा जाता है।
- व्यावसायिक समस्या के समाधान के लिए आवश्यक जानकारी निकालने के लिए विभिन्न टेबलों को जॉइन करके एक समरी टेबल (जैसे 'vendor_sales_summary') बनाई जाती है।
- क्वेरी ऑप्टिमाइजेशन महत्वपूर्ण है, खासकर बड़े डेटासेट के साथ काम करते समय, ताकि डेटा को कुशलतापूर्वक निकाला जा सके।
- अंतिम समरी टेबल में डेटा की इनकंसिस्टेंसी (जैसे मिसिंग वैल्यू, गलत डेटा टाइप, अतिरिक्त स्पेस) को Python का उपयोग करके ठीक किया जाता है।
- विश्लेषण को बेहतर बनाने के लिए नए फीचर्स (जैसे ग्रॉस प्रॉफिट, प्रॉफिट मार्जिन, स्टॉक टर्नओवर, सेल्स-टू-परचेस रेशियो) बनाए जाते हैं।
- आउटलायर्स को पहचाना जाता है और डेटा की गुणवत्ता सुनिश्चित करने के लिए उन्हें संभाला जाता है।
- क्लीन किए गए और संवर्धित डेटा को वापस डेटाबेस में एक नई टेबल के रूप में सहेजा जाता है।
- Python का उपयोग करके अंतिम डेटासेट पर विस्तृत एक्सप्लोरेटरी डेटा एनालिसिस (EDA) किया जाता है।
- डेटा के वितरण, आउटलायर्स और विभिन्न न्यूमेरिकल कॉलम के बीच सहसंबंध को समझने के लिए हिस्टोग्राम, बॉक्स प्लॉट और हीटमैप जैसे विज़ुअलाइज़ेशन बनाए जाते हैं।
- व्यावसायिक समस्या से संबंधित रिसर्च प्रश्नों के उत्तर खोजने के लिए डेटा का विश्लेषण किया जाता है, जैसे कि टॉप परफॉर्मिंग वेंडर्स और प्रोडक्ट्स की पहचान करना।
- हाइपोथिसिस टेस्टिंग (जैसे टी-टेस्ट) का उपयोग करके विभिन्न समूहों (जैसे हाई-परफॉर्मिंग बनाम लो-परफॉर्मिंग वेंडर्स) के बीच महत्वपूर्ण अंतरों का पता लगाया जाता है।
- Python में किए गए विश्लेषण के आधार पर Power BI में एक इंटरैक्टिव डैशबोर्ड बनाया जाता है।
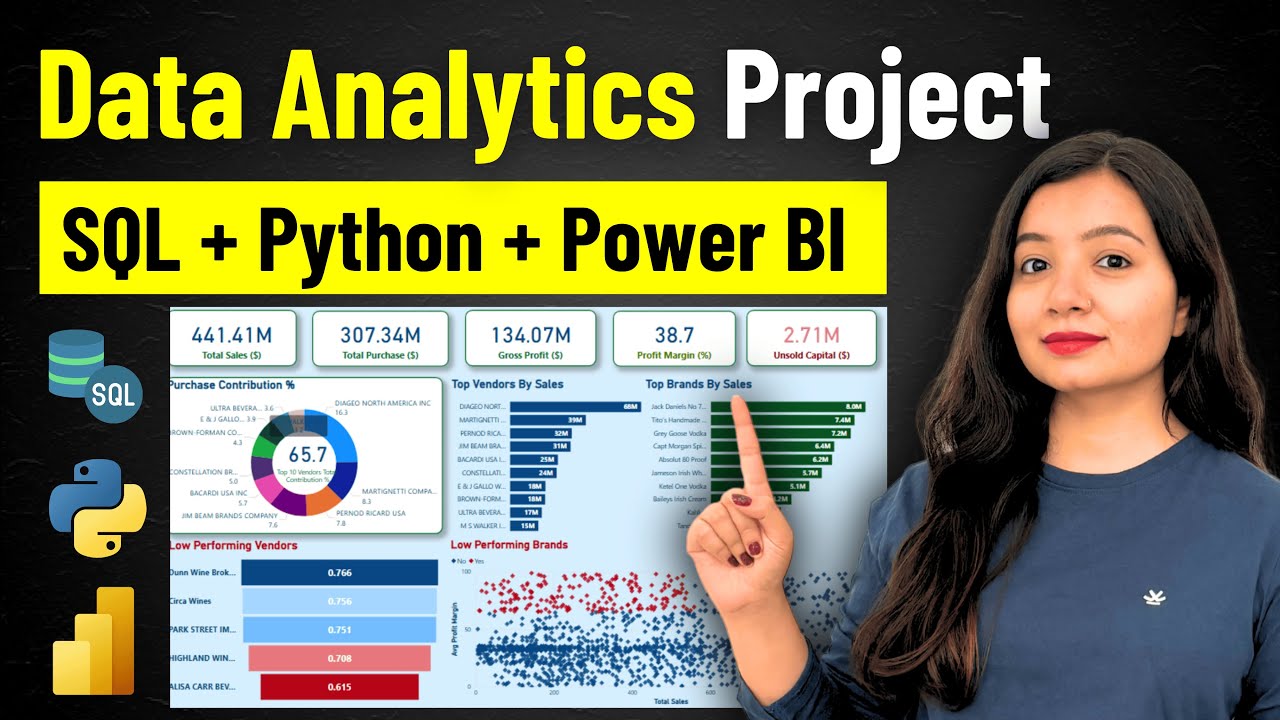
- डैशबोर्ड में प्रमुख प्रदर्शन संकेतक (KPIs), चार्ट और विज़ुअलाइज़ेशन शामिल होते हैं जो वेंडर के प्रदर्शन, बिक्री, लाभप्रदता और इन्वेंटरी को दर्शाते हैं।
- विश्लेषण के निष्कर्षों को हितधारकों (जैसे प्रबंधन, क्लाइंट्स) के सामने प्रस्तुत करने के लिए एक रिपोर्ट तैयार की जाती है।
- यह अंतिम चरण डेटा को कार्रवाई योग्य इनसाइट्स में परिवर्तित करता है जिसे व्यावसायिक निर्णय लेने के लिए उपयोग किया जा सकता है।
Key takeaways
- वास्तविक दुनिया के डेटा एनालिटिक्स प्रोजेक्ट्स में डेटा को विभिन्न स्रोतों से एकीकृत करना, साफ करना और विश्लेषण करना शामिल है, जो केवल बेसिक EDA या डैशबोर्ड बनाने से कहीं अधिक है।
- SQL, Python और Power BI जैसे उपकरणों को एक साथ प्रभावी ढंग से उपयोग करना डेटा एनालिस्ट के लिए महत्वपूर्ण है ताकि एंड-टू-एंड समाधान प्रदान किया जा सके।
- बड़े डेटासेट को संभालने के लिए डेटाबेस का उपयोग करना और कुशल SQL क्वेरी लिखना महत्वपूर्ण है, खासकर जब डेटा को बार-बार एक्सेस करने या प्रोसेस करने की आवश्यकता हो।
- डेटा क्लीनिंग और फीचर इंजीनियरिंग विश्लेषण की सटीकता और गहराई को बढ़ाते हैं, जिससे अधिक विश्वसनीय इनसाइट्स प्राप्त होते हैं।
- विज़ुअलाइज़ेशन (जैसे हिस्टोग्राम, बॉक्स प्लॉट, हीटमैप) डेटा में पैटर्न, आउटलायर्स और सहसंबंधों को समझने में महत्वपूर्ण भूमिका निभाते हैं।
- व्यावसायिक समस्याओं को समझना और विश्लेषण को उन समस्याओं को हल करने के लिए निर्देशित करना डेटा एनालिस्ट की सफलता के लिए आवश्यक है।
- डेटा विश्लेषण के निष्कर्षों को स्पष्ट और संक्षिप्त रिपोर्ट और डैशबोर्ड के माध्यम से प्रभावी ढंग से संप्रेषित करना व्यावसायिक निर्णय लेने के लिए महत्वपूर्ण है।
Key terms
Test your understanding
- एक वास्तविक दुनिया के डेटा एनालिटिक्स प्रोजेक्ट में डेटा इंजेक्शन प्रक्रिया क्यों महत्वपूर्ण है और इसमें कौन से मुख्य चरण शामिल हैं?
- SQL का उपयोग करके विभिन्न टेबलों से डेटा को एकीकृत करके एक समरी टेबल बनाने के क्या फायदे हैं, खासकर जब व्यावसायिक समस्या को हल करना हो?
- Python में डेटा क्लीनिंग और फीचर इंजीनियरिंग क्यों आवश्यक है, और यह विश्लेषण की गुणवत्ता को कैसे प्रभावित करता है?
- एक डेटा एनालिस्ट के लिए Power BI में एक इंटरैक्टिव डैशबोर्ड बनाना क्यों महत्वपूर्ण है, और यह व्यावसायिक निर्णय लेने में कैसे मदद करता है?
- इस प्रोजेक्ट में वेंडर के प्रदर्शन का विश्लेषण करने के लिए किन प्रमुख मेट्रिक्स (जैसे ग्रॉस प्रॉफिट, प्रॉफिट मार्जिन) का उपयोग किया गया है और वे व्यावसायिक लक्ष्यों से कैसे संबंधित हैं?